Global Rank 3: NeurIPS 2025 Pokemon AI Competition
Published:
🏆 Achievement
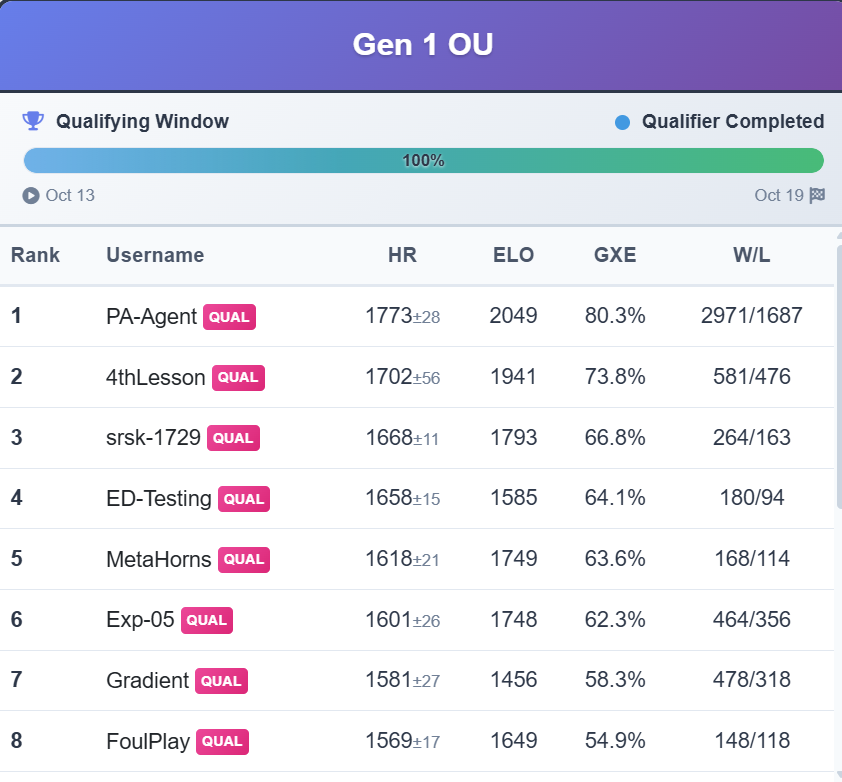
Secured Global Rank 3 (Team: srsk-1729) in Track-1 with a policy ELO rating of 1793. Our agent demonstrated superior generalization in unseen competitive scenarios, outperforming standard baselines in the official NeurIPS 2025 benchmark.
⚔️ The Challenge
The goal was to create an AI agent capable of playing competitive Pokemon battles. The challenge involves a Partially Observable Markov Decision Process (POMDP) characterized by a vast action space, hidden information (opponent moves/stats), and highly stochastic game mechanics.
🧠 Methodology
We approached this as a hybrid Imitation Learning and Offline Reinforcement Learning problem.
1. Imitation Learning with Exploration
Instead of standard Behavior Cloning, we implemented a weighted imitation objective regularized by a Q-value function. This allows the agent to mimic expert moves while exploring high-reward actions that the expert might have missed.
The Actor Loss Function: \(\mathcal{L}_{\text{Actor}} = \mathbb{E}_{\tau \sim \mathcal{D}} \left[ \frac{1}{T} \sum_{t=0}^{T} \left( -w(h_t, a_t) \log \pi(a_t \mid h_t) - \lambda \mathbb{E}_{a \sim \pi(\cdot|h_t)} [Q(h_t, a)] \right) \right]\)
- First Term (Imitation): maximizes the likelihood of expert actions, weighted by their relevance w.
- Second Term (Exploration): acts as an entropy-regularized exploration bonus, pushing the policy π towards actions with higher estimated Q-values, even if they deviate slightly from the replay-dataset.
2. Adaptive Hedge Ensemble (The Winning Edge)
To mitigate high action-entropy in ambiguous states, we engineered a policy ensemble. The system dynamically selected the most confident agent based on TD (Temporal Difference) error, allowing the bot to handle less explored scenarios robustly by switching policies when prediction error spiked.
🔗 Links
📸 Visual Library
Gameplay screenshots, reward curves, and training logs.